
BIG-IPでは、稼働中のサーバのメンテナンスをする際、既存通信への影響を最小限に抑えながら安全に切り離すことが重要です。
メンテナンス時、ロードバランサ(LB)から対象サーバを切り離す際、設定を誤ると通信断やサービス影響につながる場合があります。本記事では、BIG-IPのDisableとForce Offlineの動作や利用シーンを紹介します。
BIG-IPにおけるサーバメンテナンス時の切り離しについて
LB配下のバックエンドサーバをメンテナンスする場合、対象サーバを事前にBIG-IP側で切り離しせずに停止してしまうと、既存のアクティブコネクションや新規のコネクションにも、影響が出る可能性があります。サーバを停止する際は、あらかじめBIG-IP上で対象のNodeやPool Memberを適切な状態へ変更し、通信を制御する必要があります。
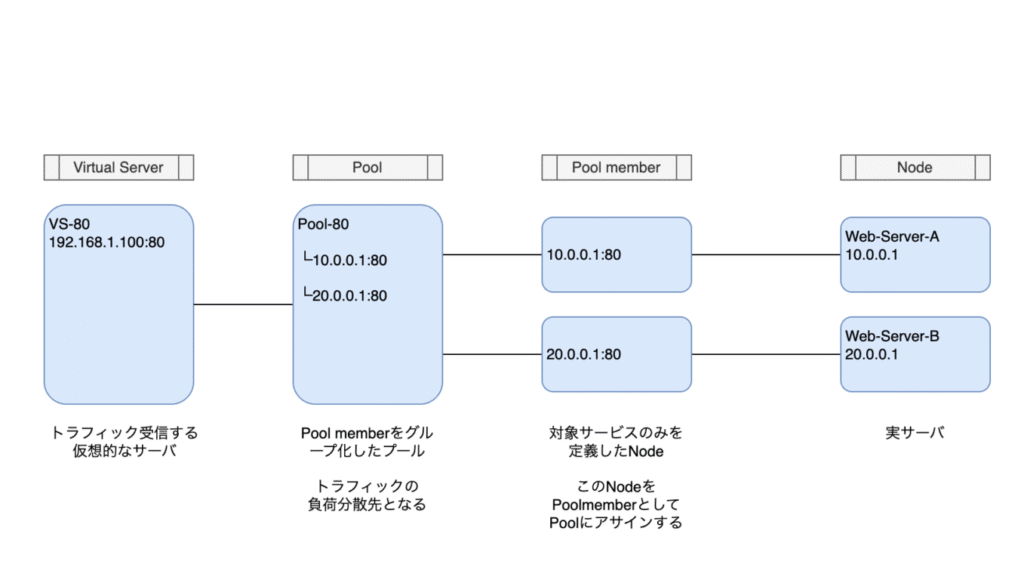
NodeとPool Memberの違い
BIG-IPでは、LB配下のサーバを管理する単位として「Node」と「Pool Member」があります。どちらもサーバを表す設定ですが、制御する範囲が異なります。
- Nodeとは
- バックエンドサーバ(IPアドレス単位)
- 独立したオブジェクト
- 複数のPoolから参照される場合がある
- Pool Memberとは
- 特定のサービスを指定したバックエンドサーバ(IPアドレス+ポート単位)
- Poolに所属するアプリケーションサーバを指す
- Virtual Serverから実際に負荷分散される対象
Nodeのステータスを変更する場合、そのNodeを参照している他のVirtual ServerやPoolにも影響します。
バックエンドサーバが複数のサービスを提供している場合は注意が必要です。
Pool Memberのステータスを変更する場合、そのサービス(ポート)だけを切り離します。
サービス単位での切り離しになるので、バックエンドサーバで提供している別サービスに対しては、影響することはありません。
| Node | Pool Member | |
|---|---|---|
| 単位 | サーバ単位 | サービス単位 |
| 対象 | IPアドレス | IPアドレス + Port |
| 影響範囲 | 広い | 限定的 |
| メンテ用途 | サーバ停止時 | 特定サービス停止時 |
ステータスの挙動(Disabled/Force Offline)
BIG-IPでは、「Node」や「Pool Member」に対して、ステータス変更することで、通信制御を行います。メンテナンス時に意識するステータスとして「Disabled」と「Force Offline」があります。
Disabled
Disabledは、メンテナンスの切り離しによく利用されます。
Disabledにすれば、セッション維持が必要なサービスにおいても、サービスを継続することができ、通信は徐々にドレインされますので、安全に切り離しすることができます。
Disabledステータスは、変更対象(NodeもしくはPool Member)が、通常の負荷分散対象から除外される状態となります。
各コネクションにおける動作について、
新規コネクションは、Enabledステータスである別のサーバへ送信されます。
既存コネクションは、Disabledにしても、継続して同じサーバとのセッションを維持するため、サービスは継続して利用することができます。
Persistence情報が存在する場合は、新規コネクションであっても、既存のPersistence情報に基づき、引き続き、同じサーバへ送信される可能性があります。
Force Offline
Force Offlineは、Disabledよりも強い切り離しとなり、メンテナンスや障害対応時に利用されます。
Force Offlineにすると、Persistence情報による振り分けも停止されますので、Disabledよりも確実な切り離しが期待できます。
Force Offlineステータスは、変更対象(NodeもしくはPool Member)が、通常の負荷分散対象から除外される状態となります。
各コネクションにおける動作について、
新規コネクションは、Disabledの時と同様、Enabledステータスである別のサーバへ送信されます。
既存コネクションは、Force Offlineにしても、継続して同じサーバとのセッションを維持するため、サービスは継続して利用することができます。
ただし、Persistence情報が存在する場合は、Disabledと動作が異なり、Force Offlineされたサーバへ新規コネクションが送信されることはありません。
別のサーバへ、通信はいつ移るのか?
まず前提としてBIG-IPでは、既存セッションを勝手に負荷分散先を変える(別のサーバへ送信する)ようなことはありません。
既存セッションが終了し、新しいリクエストが発生するタイミングで、通常の負荷分散の動きになり、既存とは別のサーバへ送信されます。
Persistene情報が残っている場合でも、Persistence Timeoutが切れるまで、基本的には同じサーバへ送信し、Persistence情報が消えたあと、別のサーバへ送信するようになります。
ただし、Persistence Timeoutが長いサービスでは、すぐに利用者は消えないので、そこを考慮してForce OfflineやPersistence設定変更を検討しておく必要があります。
BIG-IPでの設定方法
【GUI】設定方法(Node)
- Local Traffic > Nodesより対象のNodeを選択
- 対象のNodeのStatusを変更
※Enabledが負荷分散対象となるので、負荷分散対象から除外するには、DisabledもしくはForce Offlineに変更します。 - Updateボタンをクリック
- HA構成であれば、通常のSync操作も行ってください。
【GUI】設定方法(Pool Member)
- Local Traffic > Poolsより対象のPoolを選択
- Membersタブを開く
- 対象のPool MemberのStatusを変更
※Enabledが負荷分散対象となるので、負荷分散対象から除外するには、DisabledもしくはForce Offlineに変更します。 - Updateボタンをクリック
- HA構成であれば、通常のSync操作も行ってください。
【CLI】設定方法(tmsh)
設定変更コマンド:
#Node Disabledの場合
modify ltm node <Node> session user-disabled
#Node Force Offlineの場合
modify ltm node <Node> session user-disabled state user-down
#Node Enableの場合
modify ltm node <Node> session user-enabled state user-up
設定例:modify ltm node 10.0.0.1 session user-enabled state user-up
#Pool Member Disabledの場合
modify ltm pool <Pool Name> members modify { <Pool Member> { session user-disabled } }
#Pool Member Force Offlineの場合
modify ltm pool <Pool Name> members modify { <Pool Member> { session user-disabled state user-down } }
#Pool Member Enableの場合
modify ltm pool <Pool Name> members modify { <Pool Member> { session user-enabled state user-up } }
設定例:modify ltm pool Pool-80 members modify { 10.0.0.1:80 { session user-enabled state user-up } }
確認コマンド:
#Node確認の場合
list ltm node
show ltm node
#Pool Member確認の場合
show ltm pool <Pool Name> members
保存コマンド:
save sys config※Commit操作なく、設定は即時反映されますが、startup-configに残す場合は、Saveを実行してください。
HA同期コマンド:
run cm config-sync to-group <device-group>参考サイト

いかがでしたでしょうか。
最後まで、お読みいただきありがとうございました。
コメント